

What Databases Knew All Along About LLM Serving
Your inference stack is burning money on solved problems. A storage hierarchy would fix the part you’re paying for twice.


Every database engineer who has spent a year in production knows the hierarchy. Hot data lives in memory. Warm data sits on SSD. Cold data goes to disk. You don’t query the archive for a dashboard refresh, and you don’t keep last quarter’s analytics in RAM. Good ol’ common sense, refined over forty years of systems engineering, battle-tested across millions of deployments.
LLM inference in 2026 is still catching up to this lesson. Some managed APIs and production stacks have started implementing prefix caching, but the default pattern for many applications, sending the full prompt and conversation history on every turn, still causes massive redundant computation. And the bill is real.
When a user sends a query to an LLM, the model performs a computation-heavy phase called “prefill,” where it processes the entire input context and generates internal state called the KV cache, an intermediate representation of what the model has “understood” so far. This KV cache is then used during the “decode” phase, where tokens are generated one at a time. When the query finishes, this KV cache, often gigabytes of carefully computed state, is thrown away. The next query with the same system prompt, same RAG documents, same context? The model recomputes the whole thing from scratch.
This is like dropping the buffer pool after every query and rebuilding it from cold storage on the next request.
The Scale of the Waste
To appreciate why this matters, consider how KV cache actually scales. The size per token follows a straightforward formula: 2 (K+V) × layers × kv_heads × head_dim × bytes_per_element. For a LLaMA-70B model with GQA (80 layers, 8 KV heads, 128 head_dim, FP16), that works out to roughly 0.33 MB per token. A 2048-token context generates about 660 MB of KV cache. That sounds modest for a single request, until you consider context length scaling: at 32K tokens it’s around 10 GB, at 128K it’s roughly 40 GB, per sequence. And this is before you factor in batch sizes. Serve 64 concurrent requests at 8K context and you’re looking at 160+ GB of KV cache across the batch (0.33 MB/token × 8,192 tokens × 64 ≈ 173 GB), easily exceeding the capacity of a single GPU’s memory.
The real cost isn’t just memory, though. It’s the compute spent producing that KV cache in the first place. In a multi-turn conversation where the system prompt and conversation history are shared across turns, the model recomputes the same KV cache for the shared prefix every single time. If you’re running a RAG pipeline, popular retrieved document chunks get prefilled across different user queries all day long. An agent system with a fixed system prompt and tool definitions recomputes the identical context on every invocation. A customer support chatbot with a company knowledge base? Same story, thousands of times a day.
The prefill phase is compute-bound and expensive. It’s the reason users stare at a blank screen waiting for the first token. Every redundant prefill is wasted GPU-seconds, wasted electricity, and wasted user patience.
Database engineers solved a version of this problem in the 1980s. The solution was called a buffer cache. The analogy isn’t perfect: unlike database buffer pages, which can serve many different queries with overlapping access patterns, KV cache reuse requires exact prefix token matches. Same tokens, same order, same formatting, down to whitespace and special tokens. It’s a stricter cache-hit condition than most engineers expect.
What counts as “the same prefix” is worth spelling out, because this is where implementations quietly break. The cache key is the token sequence, not the text. The same English sentence tokenized by two different model versions can produce different token IDs, which means a cache miss. Chat templates matter: the <|system|> markers, role tags, and tool call scaffolding that your serving framework wraps around the raw prompt are all part of the prefix. Change the template version, reorder the tool schemas in your function definitions, or normalize whitespace differently, and your hit rate drops to zero. Model upgrades, engine upgrades, and even truncation policy changes all invalidate the cache silently.
The core principle, though, is the same as in databases: don’t recompute what you’ve already computed. You just need to be precise about what “already computed” means.
What’s The Missing Layer
A research group working on LMCache has built what is essentially a buffer management system for LLM inference. The core idea is disarmingly simple: extract the KV cache from the inference engine, store it, and reload it when the same context appears again. Skip the prefill. Serve from cache.
If this sounds trivial, that’s because it conceptually is. The difficulty is entirely in the engineering.
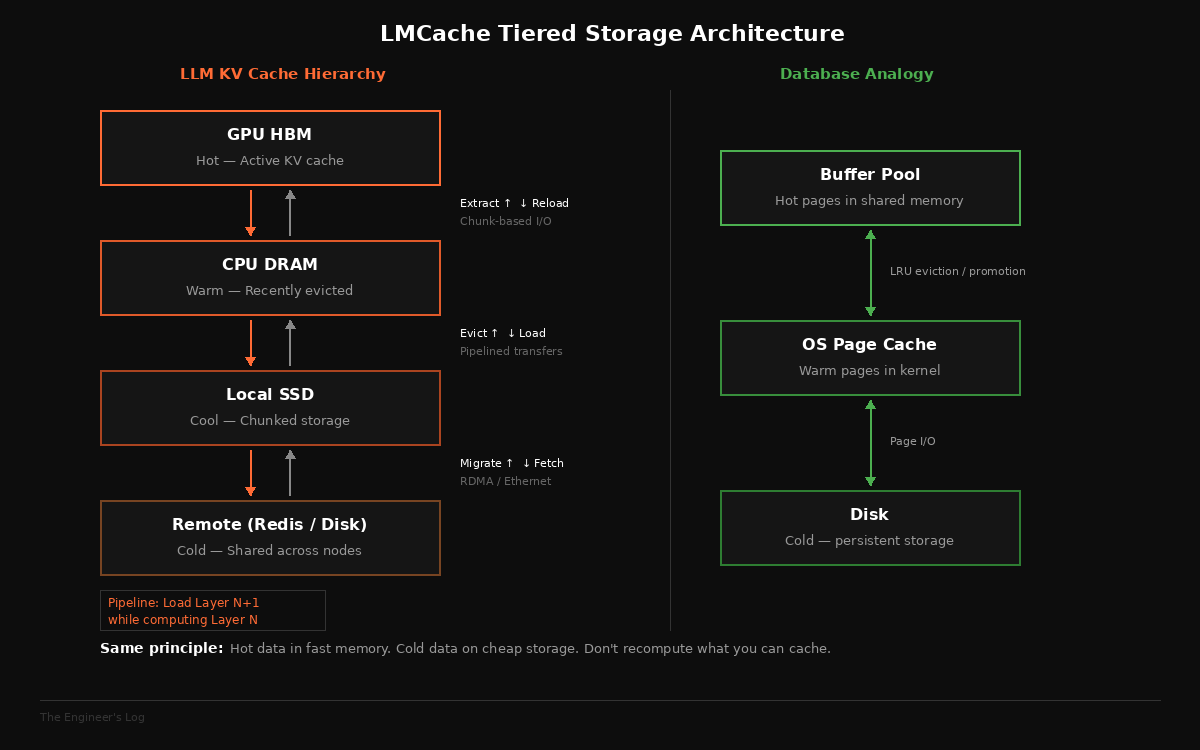
Modern LLM inference engines like vLLM and SGLang use a paged memory system for KV cache, similar to how operating systems manage virtual memory. vLLM’s PagedAttention, for instance, stores KV cache in non-contiguous memory blocks on the GPU. This is great for memory utilization within a single engine. But it makes extracting and moving KV cache across queries, across engines, or across machines extremely painful.
The page size is small. Reading KV cache at that granularity involves many tiny I/O operations, each with its own overhead. Moving data between GPU memory, CPU memory, disk, and network becomes a mess of fragmented transfers that can’t saturate the available bandwidth. It’s like trying to back up a database by reading one row at a time instead of streaming pages.
LMCache addresses this with a technique any storage engineer would recognize: chunk-based I/O. Rather than operating at the inference engine’s native page granularity, it batches KV cache into configurable chunks, much larger than individual pages, to fully utilize the bandwidth between storage tiers. The system pipelines compute and I/O, loading the next transformer layer’s KV cache from storage while the GPU is computing with the current layer. And it implements zero-copy data movement where possible, avoiding redundant memory copies as data flows through the hierarchy.
These are not novel ideas. They are proven patterns from decades of storage systems engineering, applied to a new data type.
Anatomy of LMCache
The system has two core components: a worker (the data plane) and a controller (the control plane). The worker handles the actual movement of KV cache data between tiers: GPU memory, CPU memory, local disk, remote disk, Redis, and across the network via Ethernet, RDMA, or NVLink. The controller exposes management APIs for higher-level orchestration.
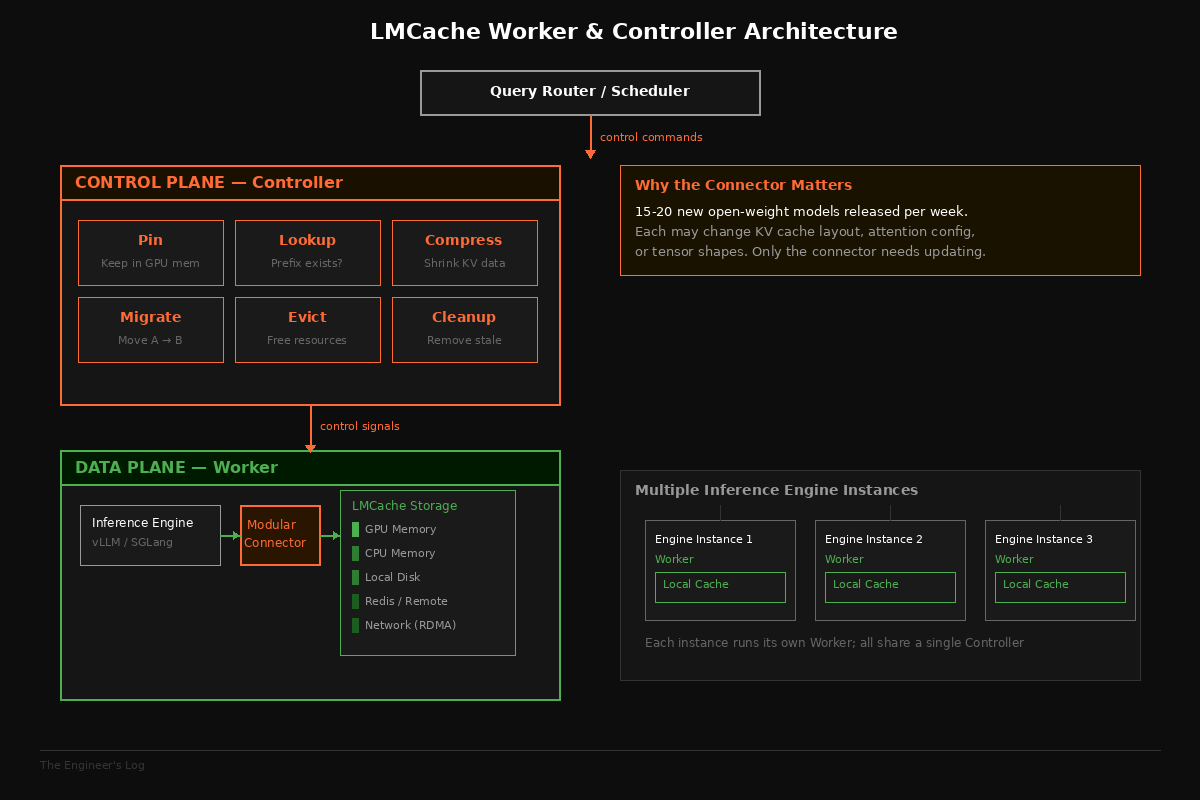
The controller is where things get interesting. It provides a set of primitives that will look very familiar to anyone who has managed a database or cache cluster: pinning (keep this KV cache in GPU memory, don’t evict it), lookup (does this prefix exist in cache?), compression (shrink this KV cache for cheaper storage or transfer), migration (move this cache from node A to node B), and cleanup (evict stale entries). These are first-class APIs, not afterthoughts.
The LMCache paper reports that a financial services company deployed the system in production and specifically requested the pinning API. Their use case: frequently accessed financial documents whose KV cache should never be evicted, because recomputing the prefill for a 50-page regulatory filing every time someone asks a question about it is expensive and slow. Pinning solved that. The same way you’d use pg_prewarm to keep critical table pages in the PostgreSQL buffer pool, they pin critical document contexts in GPU memory.
The paper also describes an agent infrastructure company that requested a different set of APIs: the ability to identify a specific KV cache by content, compress it, and transfer the compressed representation to another node. Their agents run across a distributed cluster, and when an agent’s execution migrates from one node to another, they need to move the agent’s accumulated context along with it. Without this, every migration triggers a full recomputation of the agent’s context, which kills latency.
These are not hypothetical scenarios. These are production deployment requirements that emerged from real companies running real workloads. The requests are instructive because they reveal what inference infrastructure is actually missing: not smarter models, but smarter plumbing.
Two Problems LMCache Solves
There are two distinct ways KV cache reuse improves inference, and conflating them is a common mistake.
The first is cross-query prefix caching. When multiple queries share a common prefix, such as the same system prompt, the same RAG context, or the same conversation history up to the current turn, the KV cache for that shared prefix can be computed once and reused. This directly reduces time-to-first-token and GPU utilization during prefill. If your chatbot’s system prompt is 2000 tokens and you serve 10,000 queries per hour, that’s 10,000 redundant prefill computations of the same 2000 tokens, eliminated.
The second is prefill-decode disaggregation. The prefill phase is generally compute-bound (it wants GPU FLOPS). The decode phase is generally memory-bound (it wants memory bandwidth for reading KV cache). The exact boundary depends on batch sizes, sequence lengths, and hardware, but the mismatch is real enough that colocating both on the same GPU forces you to overprovision for one phase and underutilize during the other. The industry response has been to split them: run prefill on one set of nodes optimized for throughput, then transfer the computed KV cache to another set of nodes optimized for low-latency decoding. But this requires efficient, low-overhead KV cache transfer across nodes, which is precisely what LMCache provides.

In both cases, the fundamental operation is the same: extract KV cache, store it somewhere, move it somewhere else, reload it. This is a storage and data movement problem. The AI part, the actual inference, barely changes.
The Connector Problem
Here’s a complication that rarely gets discussed in research papers but dominates real engineering effort: inference engines change constantly.
The LMCache authors report that 15 to 20 new open-weight models are released every week in 2025. Each new model may change the internal KV cache layout, the attention head configuration, or the tensor shapes. vLLM and SGLang ship updates frequently, sometimes changing their internal memory management. Any external system that reads or writes KV cache tensors directly must track these changes or break silently.
LMCache handles this with a modular connector interface. The connector is a thin abstraction layer that translates between LMCache’s internal representation and whatever the current inference engine expects. When vLLM changes its KV cache layout, only the connector needs updating, not the entire caching infrastructure.
This is a mundane but critical design decision. It’s the same principle behind database drivers, JDBC, ODBC, the proliferation of connector interfaces that let client applications survive backend changes. The alternative, coupling your caching layer directly to inference engine internals, is the kind of shortcut that works for a demo and collapses under production churn.
Looking At The Numbers
Combined with vLLM, the paper reports up to 15x throughput improvement on workloads like multi-round question answering and document analysis. Latency drops by at least 2x across prefix caching and disaggregation scenarios, evaluated against trace-driven workloads with production-representative query distributions.
The throughput improvement sounds dramatic, but it makes intuitive sense. If a large fraction of your prefill computation is redundant because queries share common prefixes, eliminating that redundancy doesn’t just save prefill time; it frees GPU capacity to serve more concurrent decode operations. Caching gains often compound rather than just adding up linearly. Though this is bounded by other bottlenecks: decode bandwidth, scheduler limits, network throughput, and actual cache hit rates in your specific workload.
The latency improvement matters more for user experience. Time-to-first-token is what users perceive as “the AI is thinking.” Cutting that in half, or eliminating it entirely for cache-hit queries, is the difference between an AI assistant that feels sluggish and one that feels responsive. Every database engineer who has tuned a query from 200ms to 20ms knows this feeling.
What This Means for Your Stack
If you run any LLM-based application with repeated context, and nearly every production application does, you are almost certainly paying for redundant computation. The more your queries share common prefixes, the larger the waste. RAG pipelines, agent systems, multi-turn conversations, document analysis, code completion with shared repository context: these are all workloads where prefix caching would pay for itself immediately.
The practical question is whether the complexity of adding a caching layer is worth the savings. The answer depends on your scale and workload, but the threshold is lower than you might expect. Even at modest query volumes, the latency improvement from cached prefill is noticeable. At higher volumes, the cost savings from reduced GPU utilization are material.
Worth noting: caching doesn’t help everywhere. If your queries have high prompt diversity with little prefix overlap, hit rates will be low and the caching overhead isn’t justified. Aggressive context truncation, where you trim conversation history to fit context windows, breaks prefix continuity and kills reuse. RAG pipelines with highly varied retrieval results per query will see lower hit rates than chatbots with fixed system prompts. And multi-tenant systems need to be careful about isolation: you do not want one tenant’s cached prefix leaking to another. These are engineering constraints, not arguments against caching, but they determine where the payoff actually lands.
LMCache is open source and integrates with both vLLM and SGLang, which are two of the most widely used open-source inference engines. The integration path is reasonably straightforward if you’re already running one of these engines. If you’re using a managed inference API, the equivalent concept exists as “context caching” in Google’s Gemini API and similar offerings from other providers, but with less control over the cache lifecycle and storage hierarchy.
What the Savings Actually Look Like
Abstract arguments about “redundant compute” are easy to dismiss. A worked example is harder to ignore.
Say you run a customer support chatbot on LLaMA-70B. Your system prompt is 1,800 tokens, tool definitions add another 1,200 tokens, and a typical RAG chunk is 4,000 tokens. That’s 7,000 tokens of shared prefix before the user even says anything. The user’s actual message averages 80 tokens. At 0.33 MB per token, the shared prefix generates about 2.3 GB of KV cache per request. You serve 10,000 queries per hour.
The savings depend on two things: your cache hit rate and your effective prefill speed. If your prefill throughput is R tokens/sec, then skipping a 7,000-token prefix saves 7000 / R seconds of GPU time per hit. On an unloaded A100-class GPU running a 70B model with tensor parallelism, effective prefill rates in the range of 2,000-5,000 tokens/sec are common, putting per-hit savings at roughly 1.5-3.5 seconds of GPU time. Under real concurrency, prefill latency can be significantly worse due to queueing and batching contention.
Working with a conservative estimate of ~2 GPU-seconds of prefill compute per hit (not wall time) and a 65% cache hit rate (reasonable for repetitive support queries): 6,500 hits per hour × 2 seconds = 13,000 GPU-seconds per hour, or about 3.6 GPU-hours per hour. Over a day, that’s roughly 87 GPU-hours saved. At A100 pricing (depending on provider and commitment, often in the ~$1-4+/GPU-hour range), you’re looking at roughly $90-350 per day on a single chatbot deployment. Scale to multiple services and the numbers compound quickly.
The latency impact is more immediately visible than the cost savings. On an unloaded A100-class GPU, a 7,000-token prefill takes on the order of seconds. Under production concurrency, it can be worse. With a cache hit, the prefill is skipped entirely, and TTFT drops to the decode startup time, typically well under a second. Your users feel that difference on every interaction.
Getting Cache Hits in Practice
Understanding why prefix caching helps is the easy part. Actually achieving high hit rates requires deliberate prompt engineering and operational discipline.
Structure your prompts with the static prefix first: system prompt, then tool definitions, then RAG context, then the user message last. This maximizes the cacheable portion. If you put the user message in the middle and the tool schemas at the end, you’ve just made the prefix unique to every request.
Canonicalize your inputs. JSON key ordering should be deterministic. Whitespace should be normalized. If your RAG pipeline returns the same document chunks in different orders across queries, your prefixes won’t match. Sort them.
Measure relentlessly. The metrics that matter are cache hit rate, cached-token fraction (what percentage of total prefill tokens come from cache), TTFT before and after, and GPU utilization. If your hit rate is below 40%, look at what’s breaking prefix continuity before investing in infrastructure.
For multi-tenant systems, partition the cache by tenant. This isn’t optional. A shared cache without isolation is a data leak waiting to happen. If you’re storing KV cache on remote tiers (Redis, NVMe over network), encryption at rest is worth the overhead. And treat cached KV as security-sensitive state: it’s effectively model internals, and tampered cache entries could steer outputs without changing prompts. Authenticate cache entries and protect against poisoning the same way you’d protect any trusted computation input.
The Broader Pattern
There’s a tendency in AI infrastructure to treat every problem as novel. New models require new serving systems. New architectures require new memory management. New workloads require new scheduling algorithms. And this is true to an extent, the attention mechanism does create genuinely new computational patterns.
But much of what makes LLM inference expensive is not the attention mechanism itself. It’s the surrounding infrastructure: storage, data movement, caching, scheduling, resource allocation. These are problems that systems engineers have been solving for decades. The KV cache is just data. It lives in memory, can be compressed, can be moved, can be stored, can be indexed, can be evicted. The fact that it was produced by a transformer rather than a database query doesn’t change the physics of I/O or the economics of compute.
LMCache works because it recognizes this. It doesn’t try to reinvent caching. It applies existing caching principles, tiered storage, pinning, pipelining, zero-copy I/O, modular connectors, to a new data type. The engineering is careful and the performance gains are real, but the conceptual contribution is almost disappointingly simple: treat KV cache as data, and then do what you’d normally do with data.
The paper’s authors put it well in their conclusion. They envision a future where “inference is not isolated sessions but a persistent, cache-aware computation fabric,” where KV cache becomes a “core primitive for efficient, reliable, and scalable inference.” This sounds ambitious until you realize that databases have been working this way for forty years. The computation fabric is the database. The core primitive is the buffer pool. The only thing that’s changed is the shape of the data.
Perhaps the most useful lesson from LMCache is not technical at all. It’s a reminder that when facing a new engineering problem, the first question should not be “what novel technique can we invent?” but “has someone already solved a version of this?” In software systems, the answer is almost always yes. The interesting work is in the adaptation, not the invention.
Next time you’re profiling your inference pipeline and wondering why it’s slow, check whether you’re recomputing things you’ve already computed. Odds are, you are. And the fix is probably something a database engineer would have suggested on day one: add a cache, make it persistent, and manage it properly.
Some lessons don’t need to be learned twice. They just need to be applied.